Je moet de groente van HAK hebben, op die foto staan Irvine en Lambert, twee van de zes vennoten van het in Schotland gevestigde Maidsafe.net Limited.
Berners-Lee daarentegen, ten tijde van zijn uitvinding en op dit moment onderwerp van een gloednieuwe documentaire:
ForEveryone.net connects the future of the web with the little-known story of its birth. In 1989, 33-year-old computer programmer Tim Berners-Lee created the World Wide Web and his visionary decision to make it a free and accessible resource sparked a global revolution in communication.
Tim has declared internet access a human right and has called for an “Online Magna Carta” to protect privacy and free speech, extend connectivity to populations without access and maintain “one web” for all. Tim’s dramatic story poses the question: will we fight for the web we want or let it be taken away?

Berners-Lee was een paar jaar geleden ook onderdeel van de openingsceremonie van de Olympische Spelen in Londen, want net als Paul McCartney die daar ook optrad een man waar ze in Engeland trots op kunnen zijn, wilden ze maar zeggen.
Over hem weer niet veel later een notoire linkse professor die ik in een vorige reactie ook al aanhaalde:
25 things you might not know about the web on its 25th birthday
It sprang from the brain of one man, Tim Berners-Lee, and is the fastest-growing communication medium of all time. A quarter-century on, we examine how the web has transformed our lives
- The web is not the internet
- The importance of having a network that is free and open
- Many of the things that are built on the web are neither free nor open
- The web is now dominated by corporations
- Web dominance gives companies awesome (and unregulated) powers
- The web should have been a read-write medium from the beginning
- The web would be much more useful if web pages were machine-understandable
- The web needs a micro-payment system
- We thought that the HTTPS protocol would make the web secure. We were wrong
- Tim Berners-Lee’s boss was the first of many people who didn’t get it initially
- The web has been the fastest-growing communication medium of all time
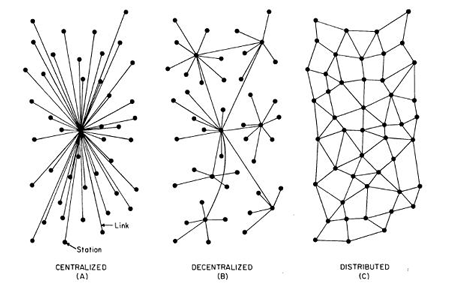
Onder verwijzing naar de oorspronkelijke opzet van het internet, dat is Internet, niet het Web, had genoemde Lambert namens MaidSafe het stokje overgenomen:
The Internet is broken
The fact that the Internet has grown beyond the expected use cases of the original design is, at the very least, a strong motivation to consider a renewed architecture. It is evident looking back that the current volume of 2.8 billion regular users was not anticipated, nor was the original design of ARPANET centralising. In fact, one of Bob Kahn’s fundamental rules, when designing the transmission control protocol (TCP), was that there would be no global control at the operations level. However, some of these principles took a back seat as other considerations took priority.
It was originally envisioned, back in the late 1960s, that there would be multiple independent networks and as Leiner et al suggested “256 networks would be sufficient for the foreseeable future”. This was clearly in need of consideration when Local Area Networks (LANS) began to appear in the late 1970s. The addition of workstations, PCs and Ethernet technology, in addition to LANs, also led to changes in the original architecture concepts. The rapid and unforeseen rise in the Internet’s growth introduced scaling issues that were dealt with by the implementation of a hierarchical routing model. This approach led to a centralising of the architecture, with the introduction of “managed interconnection points” by US Federal agencies.
This enabled more “rapid configuration robustness and better scaling to be accommodated”. As the National Science Foundation (NSF) started to privatise and commercialise the program in 1995, the use of regional networks via private long haul carriers led to the information superhighway. This made the world wide web, envisioned by Tim Berners-Lee, possible.
However, as the Internet has continued to grow, it is suggested that this change in direction has led to some significant problems that not only impact upon the way the world’s citizens manage data, it is also having a much more profound impact on society as a whole.
The SAFE Network - a New, Decentralised Internet - October 2-3, 2014
Een ‘hostile environment’ schreven ze:
Data in a hostile environment
It is also worth considering the robustness that the SAFE network provides. As the network is comprised of the resources of its users, as opposed to a central location, it cannot be turned of and no kill switch exists. Furthermore, the network does not use the Domain Name System (DNS), making it impervious to web censoring.
All SAFE traffic exists as fully encrypted UDP packets. This implements Net Neutrality at the core of the SAFE network. All data packets are indistinguishable and can only be treated equally.
En sambal maak je van hete pepers:
Adoption challenges
Attacks can also take a non-technical form. For example, public relations efforts to discredit the network to the public, slowing and even halting adoption are a possibility.
Removing advertising as a default form of payment for online services will also require significant adjustment and many companies who experience success with the status quo might be resistant to change.
However, it is important that the SAFE network does not make the advertisement driven business model impossible. On the contrary, the SAFE network drastically cuts the infrastructure costs of online services, and a service may allow users to actively choose to pay for their usage by receiving advertisements.
The SAFE network just restores the choice to the users.
Alternatively, cryptocurrencies can be part of the solution. Innovations such as Bitcoin (currently) provide very low transaction fees, making micropayments a viable option. Accumulated micropayments can automatically be transferred to the correct rights holders, be it for text, music, movies or applications.
In een ‘paper’ of bij een voordracht altijd netjes ander werk vermelden:
Competing alternatives
MaidSafe is not the only organisation to build decentralised technologies for network infrastructure.
Established in 2000, Gnutella was one of the earliest decentralised pure peer-to-peer networks and currently supports several million users. As with the SAFE network there is no reliance on any central servers.
Freenet is another peer-to-peer network that utilises a decentralised data store that provides its users with anonymity protection and censor-resistant communications. The open source project was established in 1999 and his been in development ever since.
BitTorrent is the most popular peer-to-peer network and is, according to the company, used by an estimated 150 million users world wide. BitTorrent brings an innovative approach to the problem of scalability within P2P systems, which typically rely on source peers to provide the majority of the resource when downloading large files.
Waarna zij voorgaan in gebed:
Conclusion
The SAFE network potentially provides a solution to those looking to enjoy the vast resources of the Internet without many of the downsides, which include mass surveillance from governments and companies.
The SAFE network also aims to minimise many of the security risks that currently exist with the existing World Wide Web. The SAFE network has been implemented in a decentralised architecture and has been designed in this way to remove the requirement for human intervention from our data, while also removing servers, which act as a central point of weakness.










{kind=link}