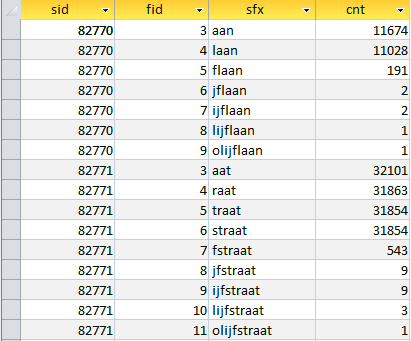
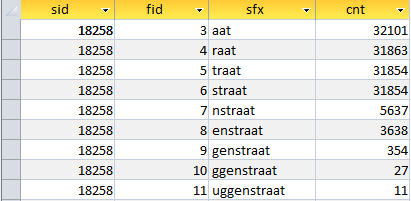
Daar is de marktmeester, tot hier en niet verder:

Oog waaraan je het zeil van een zij- of achterwand van je voor deze dag gehuurde kraam kunt vastzetten. Vanwege mogelijke neerslag en ook als een bijdehand iemand je handel achter je rug komt monsteren.
De eigenlijke straatnaam is:
openbareruimtenaam woonplaatsnaam
Dapperstraat Amsterdam
Die van domweg gelukkig, in Deventer of Tilburg:
openbareruimtenaam woonplaatsnaam
Dapperstraat Deventer
Dapperstraat Tilburg
Wat je eigenlijk ook wil doen is:
trm cnt
dapper 3
straat 3
Maar daar ga je al, dan deze ook:
openbareruimtenaam woonplaatsnaam
Bernhard Dapperstraat Diepenveen
Dapperplein Amsterdam
Dapperweg Brouwershaven
Dapperweg Burgh-Haamstede
Niet Bernard? Net als Dapper altijd een buitenbeentje gebleven:

Van stukken straatnaam een lijst ‘tokens’ maken:
trm cnt
bernhard 1
dapper 7
plein 1
straat 4
weg 2
Want? Als (delen van) woorden in zo’n bestand goed te tellen zijn kan je vervolgens proberen daar weer statistiek op los te laten.
Bestand? De volledige lijst van Nederlandse straatnamen. Blijkt dermate omvangrijk dat het ‘corpus’-achtige trekken vertoont, d.w.z. eigenlijk is de hele verzameling meteen z’n eigen woordenboek.
Waarin je eerder gevonden delen van straatnamen één voor één op andere plekken in het bestand “voorgesplitst” ziet terugkeren:
- “Straat” als straatnaam in Roermond
- "Straat " van Gibraltar en dergelijke
- Iets en " straat" los zoals in 5 Mei-Straat, Zoetermeer
- Iets anders en " straat " en nog iets als in Tijdelijke straat 37, Pernis Rotterdam
Deze straten geteld:
trm cnt
^straat$ 1
^straat_ 26
_straat$ 125
_straat_ 2
Bernard en Bernhard:
trm cnt
bernard 74
bernhard 5
Zowel het bepalende als het zelfstandige deel van een straatnaam kunnen dus ook afzonderlijk in gebruik zijn maar aangezien de laatste, “-straat”, veel vaker wel dan niet nog aan het eerste deel vastzit is die telling nergens het echte aantal, de “woordfrequentie”.
Afhankelijk van hoe je zou willen tellen kun je deze frequentie gaan bepalen in bijvoorbeeld “9999OPR08082018”, de “BAG-extract”-update van augustus:
- “straat” als het woord “straat” het eerste al of niet vrijstaande deel van een straatnaam vormt
- “straat” als “straat” als gemeld meteen ook “Straat” is als naam van een straat
- “straat” als de positie in een straatnaam, vooraan, achteraan, niet uitmaakt
- “straat” als “straat” de laatste zes letters van een straatnaam vormt
Deze nieuwe straten weer tellen:
trm frq
^straat 61
^straat$ 1
straat 77833
straat$ 77100
Z.K.H. nu aan kop:
trm frq
^bernard 98
^bernhard 169
bernard 104
bernhard 486
Waarbij je nieuwsgierig wordt naar het effect van ‘prefix’ “prins”?
trm frq
^prins 2033
prins 2204
prins$ 6
En vervolgens nog wie of wat heet er dan “prins” van achteren?
openbareruimtenaam woonplaatsnaam
De Prins Driebergen-Rijsenburg
Erfprins Oegstgeest
Gele Prins Limmen
Groote Prins Mill
Kroonprins Haaksbergen
Waren er toch zes? In de BAG heeft zes geen adres, het blijft bij een “openbareruimtenaam”:
openbareruimtenaam woonplaatsnaam
Fortgracht Erfprins Den Helder
Maar nog een keer, waarom moeite doen? Voor als je met hulp van je computer “uitspraken wil kunnen doen” over straatnamen: om wat voor naam gaat het bij “Dapper” uit “Dapperstraat” en is dat eenmalig? Ze hebben er in dezelfde plaats nog eentje maar dan als “plein” en ja, in andere plaatsen nog twee “straten” en ook nog twee als “weg”.
Oké, splits ze dan maar. Hoe? Met behulp van de methode waarbij je langs een ‘string’ loopt - hier de te splitsen straatnaam - en zegt, stop, op deze positie voeg ik er een spatie in want in deze lijst met voorbeelden geven ze aan dat het vaker zo gedaan wordt.
Op internet zijn ‘papers’ te vinden waarin iedere wetenschapper die al een keer gekeken heeft naar ‘Wordbreakers’, ‘Word boundary detection’ dan wel ‘Word Segmentation’, aanneemt dat de daarvoor benodigde woordfrequenties beschikbaar zijn of “geleerd” kunnen worden.
Voor opeenvolgende letters:
A Statistical Learning Algorithm for Word Segmentation
This paper describes a computer algorithm that is designed to solve the problem of locating word boundaries in blocks of English text from which the spaces have been removed. The algorithm relies entirely on statistical relationships between letters in the input stream to infer the locations of word boundaries.
Voor opeenvolgende delen van een woord of zin de bijdrage aan “Beautiful Data” van Peter Norvig:
Word Segmentation
Consider the Chinese text  . This is the translation of the phrase “float like a butterfly.” It consists of five characters, but there are no spaces between them, so a Chinese reader must perform the task of word segmentation: deciding where the word boundaries are. Readers of English don’t normally perform this task, because we have spaces between words. However, some texts, such as URLs, don’t have spaces, and sometimes writers make mistakes and leave a space out; how could a search engine or word processing program correct such a mistake?
. This is the translation of the phrase “float like a butterfly.” It consists of five characters, but there are no spaces between them, so a Chinese reader must perform the task of word segmentation: deciding where the word boundaries are. Readers of English don’t normally perform this task, because we have spaces between words. However, some texts, such as URLs, don’t have spaces, and sometimes writers make mistakes and leave a space out; how could a search engine or word processing program correct such a mistake?
Daar, als ik woordfrequenties uit de Nederlandse straatnamen wil halen moet ik eerst woordfrequenties hebben om die straatnamen effectief te kunnen “segmenteren”.
Dan maar met het timmermansoog proberen daaraan te komen? Te beginnen met die enkele “Straat” in Roermond en aan de hand daarvan straatnamen selecteren die op “-straat” eindigen.
Vervolgens met behulp van het gevonden “dapper” weer een straatnaam-extensie of twee, drie loskloppen:
^dapperplein$ ^dapper plein$ 1 78 19,4343
^dappersdam$ ^dapper sdam$ 1 0 23,7910
^dapperslaer$ ^dapper slaer$ 1 0 23,7910
^dapperstraat$ ^dapper straat$ 3 125 17,8640
^dapperweg$ ^dapper weg$ 2 260 17,5371
^dapperstraat$ ^dapperstraat $ 3 0 21,5937
Ik herhaal, niet meteen “dapperstraat” op basis van een onvolledige telling al daadwerkelijk splitsen maar die voorlopige telling gebruiken om “dapper” - dat nog niet op zichzelf staand voorkwam - in de context van een aantal verschillende straatnamen te valideren en eventueel als term aan mijn definitieve woordfrequentielijst toe te voegen.
Op dat moment het aantal keer dat ik het al heb zien voorkomen met 3 verhogen evenals item “straat”, net zo, 3 erbij. Item “dapperstraat” vervolgens met 3 verminderen. Die met “plein” en “weg”, rinse repeat.
Geheel rechts een hulpkolom, de ‘probability’ van “dapper” en “straat” zijnde 3 en 125 betrokken op de lengte van de bestaande lijst met woorden die al zelfstandig voorkwamen, te weten 146603.
Op gezag van “Beautiful Data”, ch. “Natural Language Corpus Data”, par. “Word Segmentation”:
If the product is higher than any other candidate’s product, then that’s the best answer.
Hier juist lager vanwege de logaritmisch verschoven werking. En ook al bestond “dapper” niet, je mag aannemen dat de frequentie tenminste 3 zal zijn want ze kwamen immers met 3 “dapperstraten”?
Aan de “-straat”-kant de term daar iets rigoureuzer laten meebeslissen, aan die kant was toch meer statistische informatie voorhanden?
Waarom naast “^dapper” en “straat$” ook “^dapperstraat” en “$” laten meelopen?
Voor gevallen als deze:
^magielshoek$ ^magi elshoek$ 1 0 23,7910
^magirusstraat$ ^magi russtraat$ 1 0 23,7910
^magispad$ ^magi spad$ 1 1 23,7910
^magistererf$ ^magi stererf$ 1 0 23,7910
^magisterhove$ ^magi sterhove$ 1 0 23,7910
^magisterstraat$ ^magi sterstraat$ 1 2 23,0978
^magistraat$ ^magi straat$ 4 125 17,5764
^magistraatwijk_ ^magi straatwijk_ 3 0 21,5937
^magistratenlaan$ ^magi stratenlaan$ 1 0 23,7910
^magistratenveld$ ^magi stratenveld$ 1 0 23,7910
^magistraat$ ^magistraat $ 4 0 21,0184
^magistraatwijk_ ^magistraat wijk_ 3 5 20,7952
Als “^magi” niet bestaat, is het dan goed als ik terugval op de combinatie “magistraat” en “wijk_” die beiden wel voorkomen alsmede het standalone “^magistraat$”?
Ga ik die toevoegen aan mijn lijst en wachten tot de meervoudsvorm in “^magistratenlaan$” en “^magistratenveld$” ook voorbijkomt.
Bestaan ze inderdaad?
openbareruimtenaam woonplaatsnaam
De Magistraat Borculo
Magistraat Brielle
Magistraat Heerenveen
Magistraat Steenwijk
Magistraat Woudrichem
Magistraatwijk I Middelburg
Magistraatwijk II Middelburg
Magistraatwijk III Middelburg
Magistratenlaan 's-Hertogenbosch
Magistratenveld Apeldoorn
Fris en fruitig:

Vond de makelaar die deze foto plaatste wel geinig maar hij bestaat zelf ook:
openbareruimtenaam woonplaatsnaam
De Makelaar Amersfoort
Makelaar Assendelft
Makelaarsbruggetje Amsterdam
Makelaarstraat Almere